Volumetric videoconferencing enables immersive six Degrees of Freedom interactions by jointly transmitting visual appearance and 3D geometry. However, delivering volumetric video over today's networks remains challenging due to high bandwidth demands, strict real-time latency constraints, and frequent packet loss. We present ReVo, a loss-resilient volumetric videoconferencing system that jointly recovers RGB and depth content under packet loss while meeting real-time constraints. It decouples volumetric video into RGB and depth streams, selectively protects critical content using network-layer FEC, and reconstructs corrupted non-critical frames using a post-decode neural recovery module. Our evaluations using real-world loss traces show that ReVo improves median SSIM by up to 32% for RGB content and 13% for depth content, and reduces video freezes by up to 95.7% compared to existing techniques.
Effective loss recovery for volumetric videoconferencing requires a cross-layer design. Application-layer recovery is powerful but conditional on having decodable frames. ReVo bridges this gap by combining targeted network-layer protection with robust neural reconstruction.
The Problem: Raw volumetric representations (like Point Clouds or NeRFs) demand too much bandwidth and encoding time for real-time interactive use.
The ReVo Solution: We decouple volumetric frames into 2D RGB and Depth streams. By projecting the 3D scene into 2D, we leverage highly efficient, existing 2D video codecs, which ensures low encode-decode latency.
The Problem: To meet strict 30 FPS playback deadlines, post-decode recovery needs something to work with. Missing I-frames or P-frame headers normally cause decoders to drop the frame entirely.
The ReVo Solution: We apply selective network-layer Forward Error Correction (FEC) only to critical data (I-frames and P-frame headers). For everything else, a deadline-driven frame assembly module feeds partially received P-frames to the decoder just in time, ensuring the neural models always receive an input.
The Problem: Different codecs produce different visual artifacts under the same loss patterns. Furthermore, corruptions in RGB (color) and Depth (geometry) behave fundamentally differently.
The ReVo Solution: We deploy separate, parallelized ML models (ViViT) for RGB and Depth. They undergo a two-stage training process and use modality-specific loss functions:
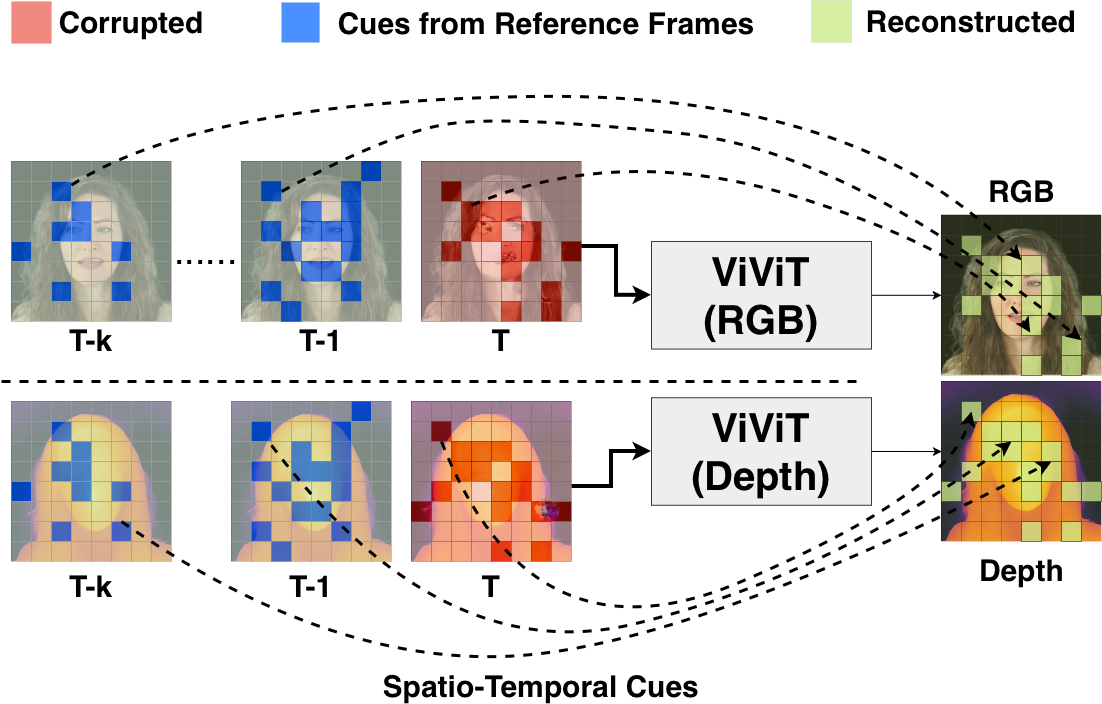
Figure 2: ViViT-based loss recovery exploiting spatio-temporal cues to reconstruct missing patches in RGB and depth frames.
Relying solely on the network layer (L3) or application layer (L7) is insufficient for the high demands of volumetric videoconferencing. A cross-layer approach is necessary to separate critical and non-critical content, effectively balancing latency, bandwidth, and visual quality. ReVo achieves this by applying selective FEC protection to crucial I-frames while leveraging neural recovery for independent P-frame losses. Compared to L3- or L7-only baselines, this strategy significantly reduces error propagation and minimizes video freezing.
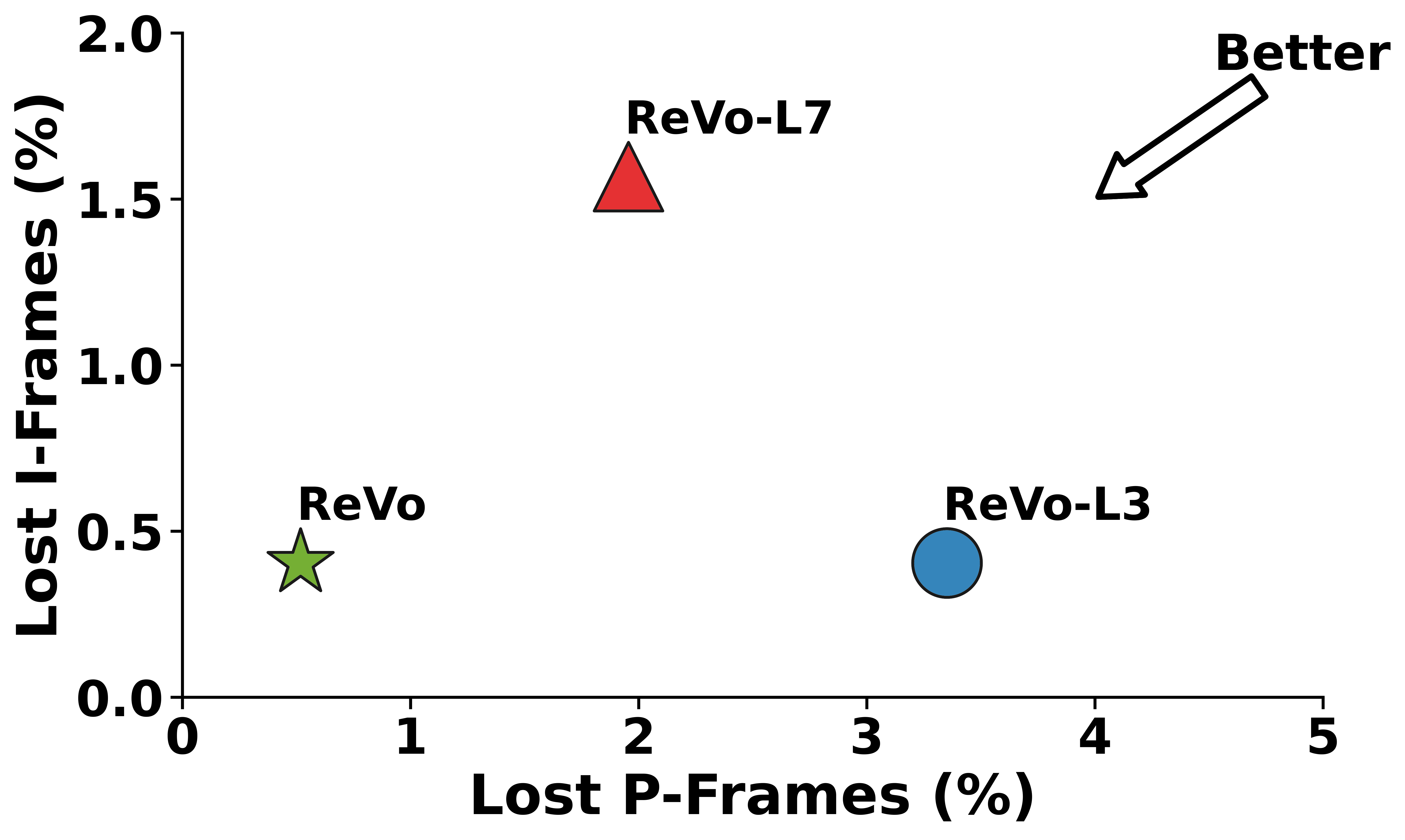
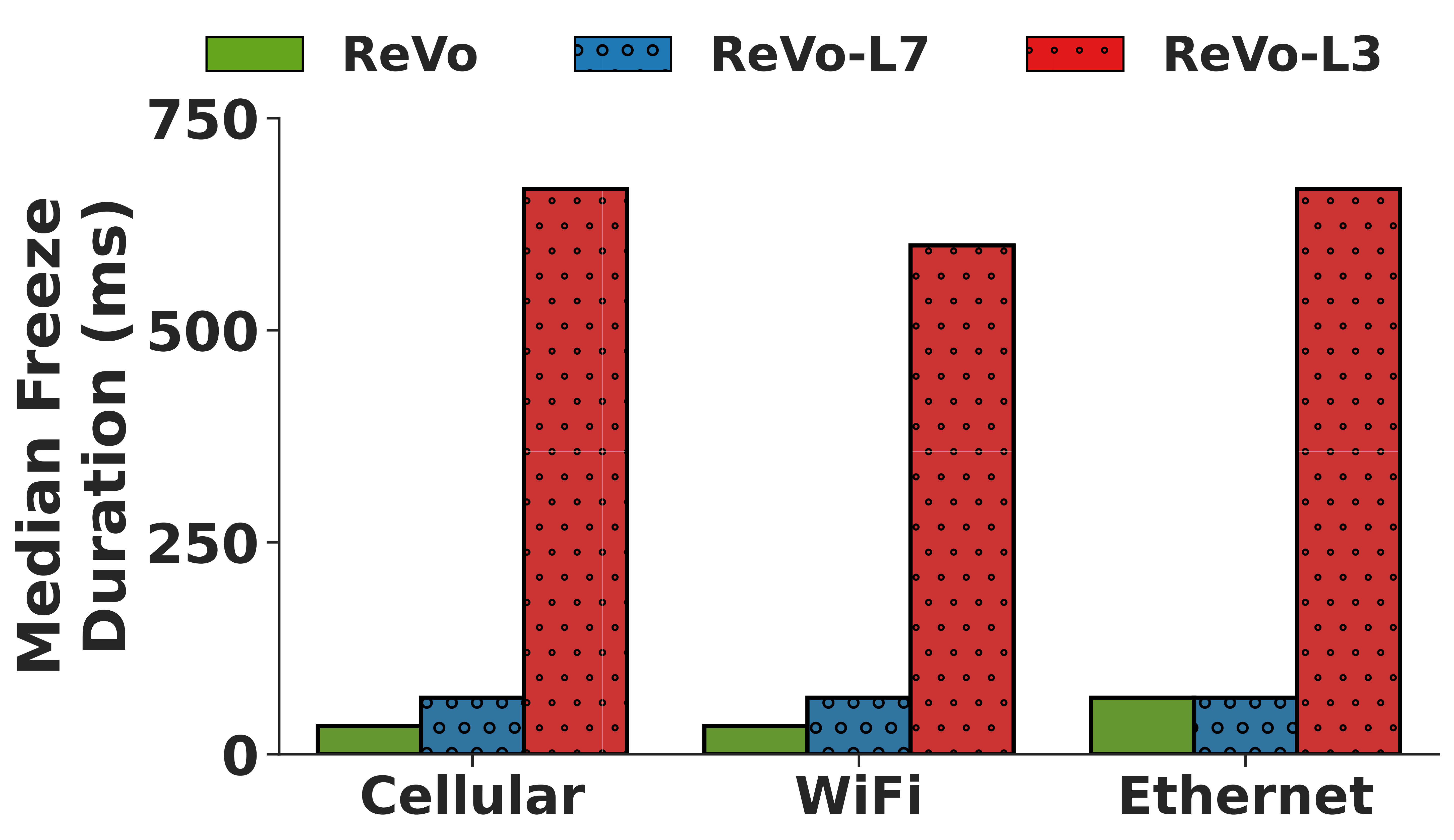

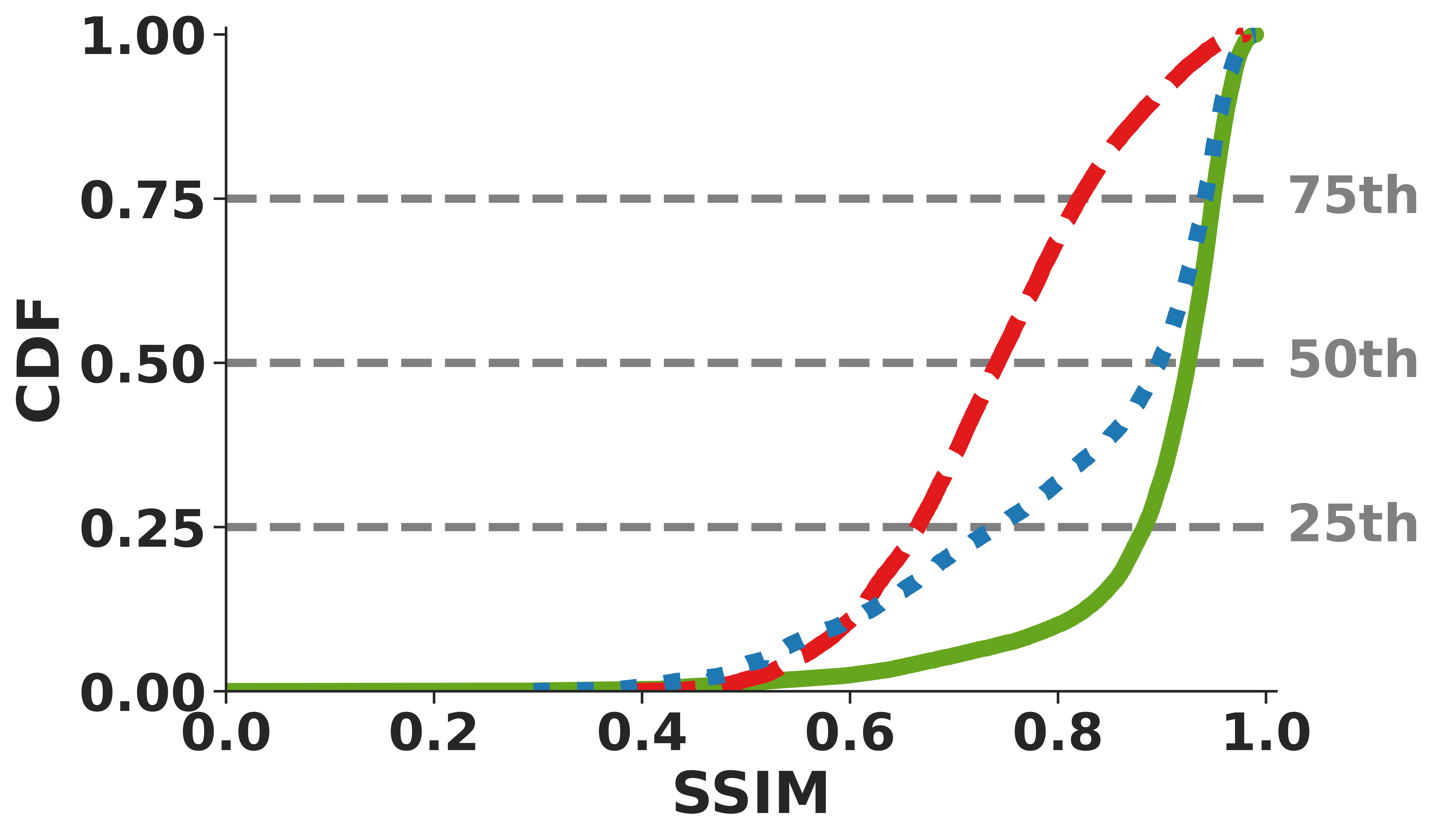
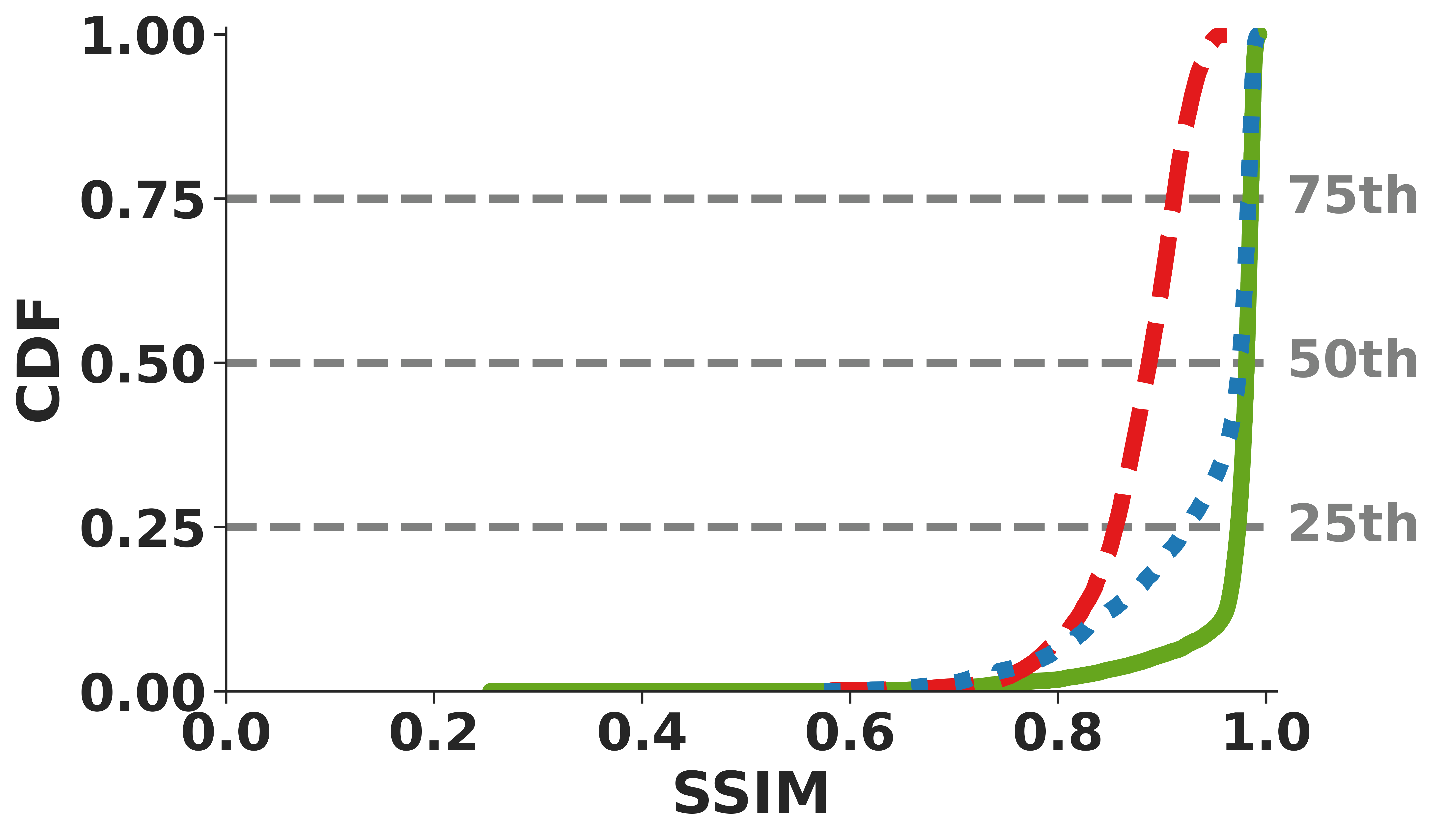
Figure 3: ReVo cross-layer recovery (a) minimizes frame losses, (b) reduces video freezes, and delivers higher-quality reconstructions for (c) RGB and (d) depth.
ReVo was extensively evaluated against state-of-the-art L3 and L7 baselines using 150 minutes of video data across real-world cellular, WiFi, and Ethernet traces from Hairpin.
Unlike many application-layer techniques, ReVo operates post-decode and successfully generalizes across traditional and neural video codecs. It consistently maintains a median SSIM over 0.90 across H.264, H.265, and DCVC-RT under identical loss conditions.

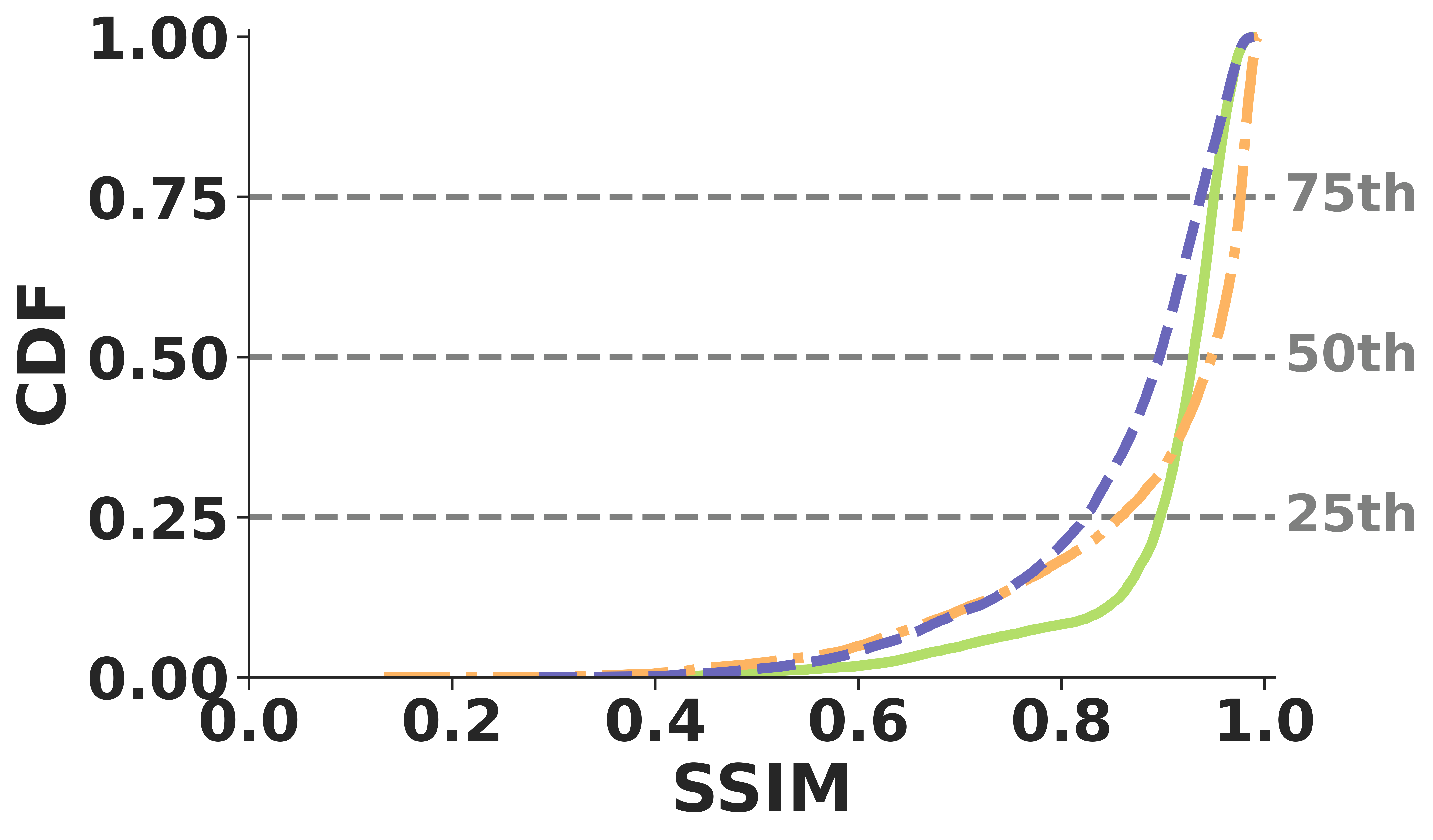
(a) RGB
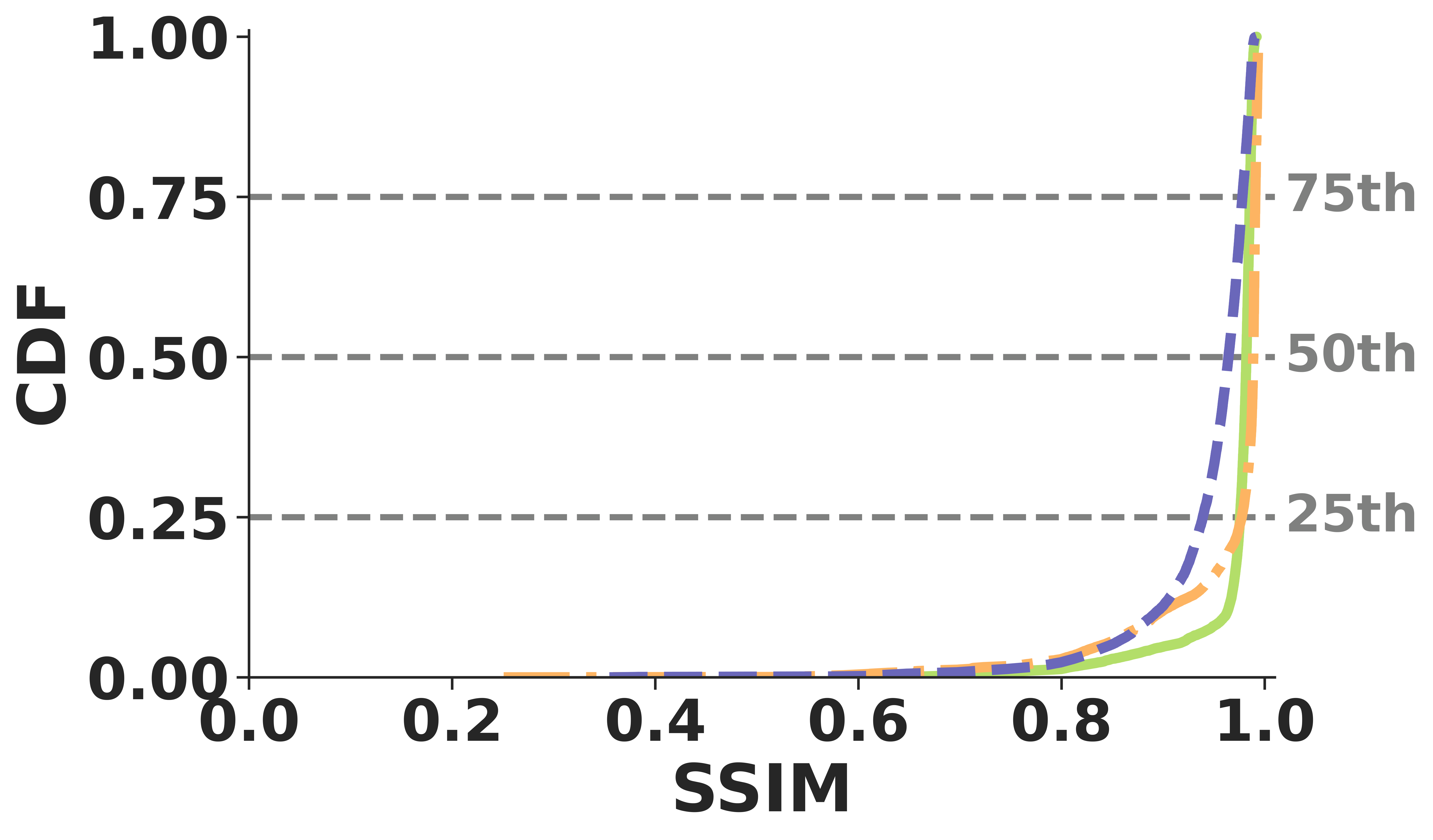
(b) Depth
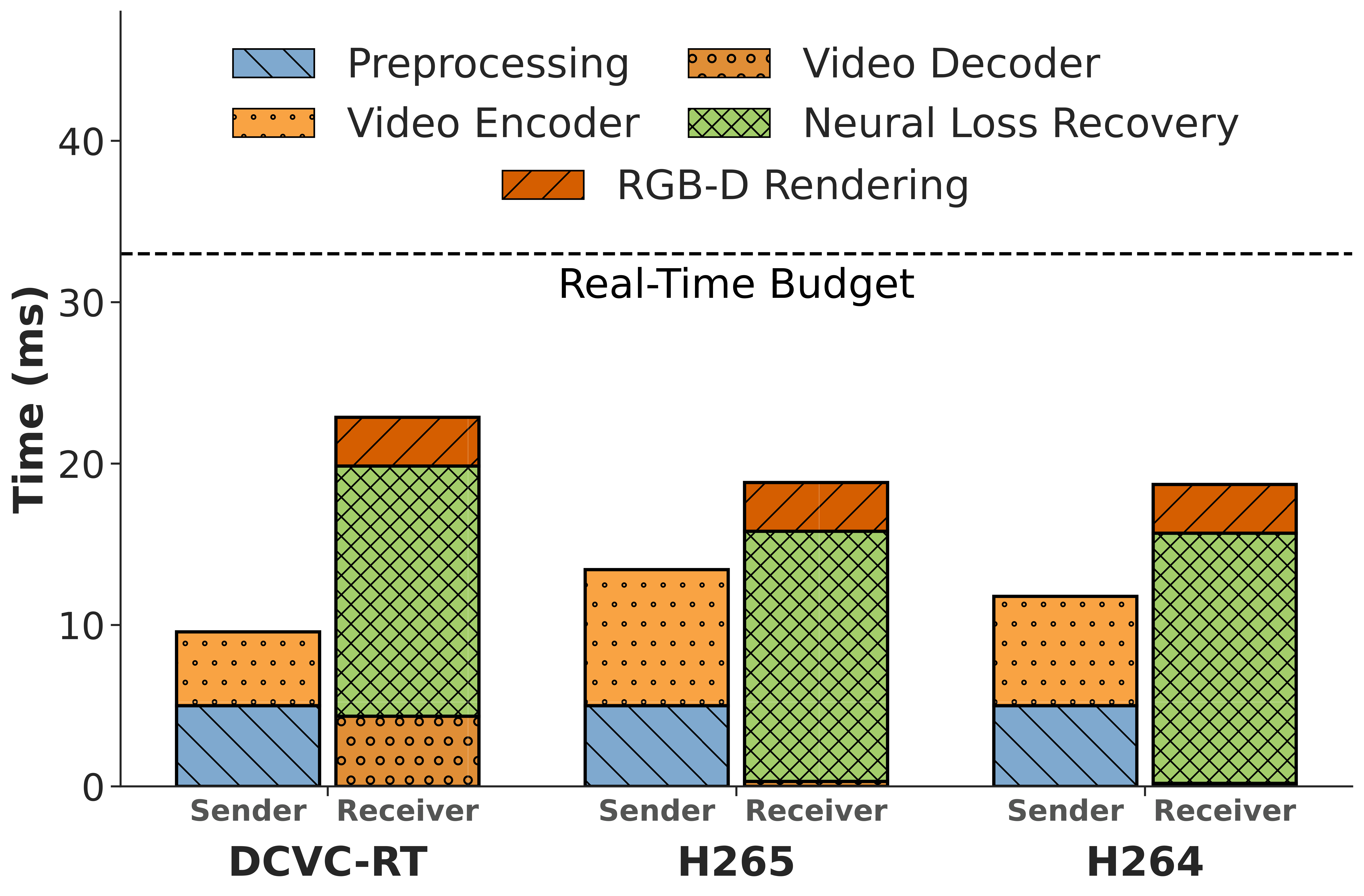
ReVo easily meets the strict 33.3 ms deadline for 30 fps interactive videoconferencing. End-to-end processing takes at-most 12 ms at the sender and 25.9 ms at the receiver on a standard desktop-grade RTX 4070 GPU.
By preventing GoP (Group of Pictures) collapses during bursty losses, ReVo reduces the median duration of video freezes by up to 95.7% and decreases the percentage of completely non-recovered frames by 86% compared to network-layer baselines like Tambur.

(a) Freeze Duration
(b) Non-Recovered
Tested across four global AWS regions (Ohio, Oregon, Frankfurt, and São Paulo) streaming to a US-East receiver, ReVo maintains robust quality over real-world Wide Area Networks. It achieves a median SSIM above 0.91 for RGB and 0.97 for depth across all regions, demonstrating high-quality volumetric video delivery under practical network conditions.

@misc{aditya2026revocrosslayerreliablevolumetric,
title={ReVo: A Cross-Layer Reliable Volumetric Videoconferencing System},
author={Ankur Aditya and Diptyaroop Maji and Lingdong Wang and Bhavya Ramakrishna and Ramesh Sitaraman and Prashant Shenoy},
year={2026},
eprint={2604.27441},
archivePrefix={arXiv},
primaryClass={cs.NI},
url={https://arxiv.org/abs/2604.27441},
}